Over 18 million frames in db today… getting this data decoded and usable should be a top priority for LSF. Thankfully, I don’t think it will be too hard if we decide to pick some tools off the shelf, and give us the added benefit of crowd-sourced visualizations.
I set up a proof of concept last weekend, thinking that the data in these frames is really a bunch of time series data (albeit irregular in frequency). This makes time series databases a perfect fit for handling our decoded data. For this POC I went with influxdb after recommendations from colleagues.
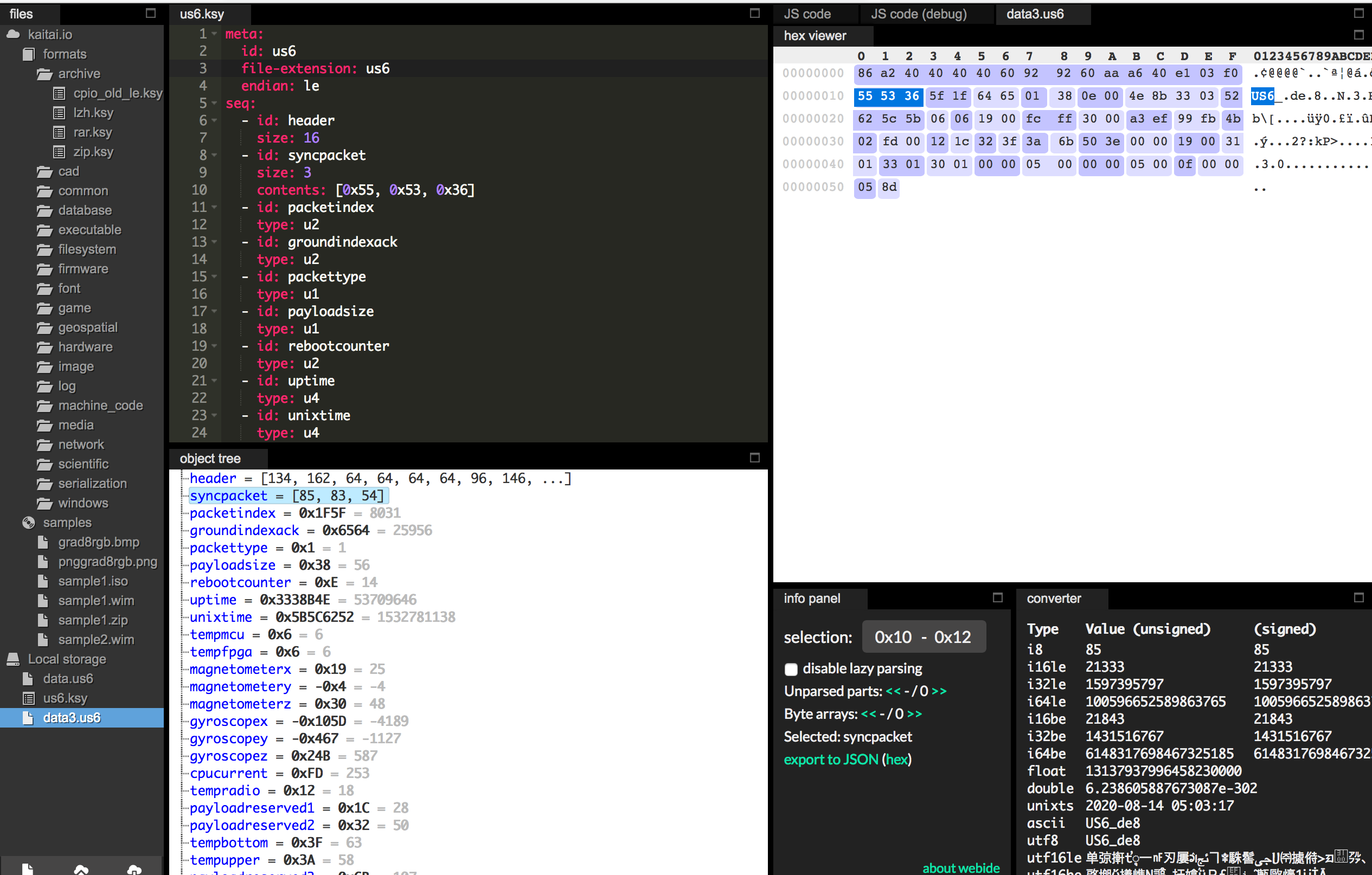
I took a month of data from db for unisat-6 (getting “all of the data” for it made db choke and I never got the email). I went with unisat-6 because we already have a decoder written for it. I modified this decoder a bit to read the data from the .csv and discard any frames that were not the telemetry we were looking for (“U S 6”).
Then, each data point was entered into influxdb with the timestamp of the frame, tagged with the satellite name. We have a ton of data for unisat-6 so in all I think some 40,000 frames were imported.
I slapped grafana on top of this and with a few clicks I had a dashboard that I could visualize, dive into, change the time scope, etc:
Now, there are some design issues in this model that need some discussing and consideration (like the data schema, tagging, etc) which is why I haven’t opened this discussion up for the broader community to pitch in on yet… but I feel this is a feasible way of getting our data out there and it shouldn’t be too hard. In fact, the visualization and data usage opportunities are endless here - especially if we open up the data via an API.
create per-satellite decoder scripts (or decode functions that we store alongside the satellite in db?).
the decoder scripts run, and as each frame is decoded it is tagged as such in the “decoded” field in db - this allows us to start decoding a satellite we have been capturing for a while now while continuing to do so for new frames that come in (select where ‘decoded’ = 0)
we stand up a grafana instance with user accounts for the community
create general dashboards for each satellite in grafana and import the dashboard iframe back into the satellite display in db.satnogs.org
if someone wants a different type of dashboard, or create a dashboard that mixes data between different satellites, they can do that themselves within grafana. The opportunities for data mining and discovery here are endless. Alerts can be setup within grafana and sat owners can be notified when events or anomalies occur.
eventually, or in parallel, middleware needs to be written to copy frames from network.satnogs.org into db.satnogs.org (I would propose we do this by writing a SIDS exporter for network.satnogs.org just to keep things simple in the db). But I don’t want this to block or derail the decoding and visualization work as we already have a majority of our data in db.
known issues
Is the per-satellite python method right? I hear of people looking into kaitai but is that going to work in our environment? The python struct unpack method does indeed work today but may be more work up front in writing the decoders, however we get more flexibility then I think we would get with kaitai (ie: skipping to the US6 in a unisat-6 packet to begin telemetry).
TSDB schema design… in my POC every data point was unique. For instance, there’s a data point called “uptime” so picking the latest data is a matter of picking the “uptime” field where the “satellite” tag is “upsat-6”. Uptime is a common field and could be common across a lot of different satellites, while some satellites may differ in terminology (and maybe that’s okay). Obviously there will be fields unique to each satellite. And, maybe in the TSDB world we don’t care as long as the fields are programmatically decoded and properly tagged.
tagging needs to be thoroughly discussed and agreed upon before we import 18M records. Does the submitter become a tag? Location?.. (I forget what all we collect in db, but I know its not all exposed through the csv exporter)
how do we handle data of different types from satellites? In the unisat-6 example I only decoded telemetry packets. Maybe that’s good enough for now and all we care about.
Is a TSDB the right choice for satellites we won’t be collecting frequent data from? (I still think it is - dashboards can be “last data is ##” without the need for graphing)
I updated data from the past week and created a publicly accessible view at the url below if anyone wants to try this out. Again, this is just a proof of concept, there are probably better ways of displaying this data (or better data to display), I just threw it together in a few hours.
<@pierros> cshields: how difficult would it be to setup influxdb for network so we can have dashboards (like the ones etihwnad is doing with jupyter) ?
influxdb is dead simple to “setup”… I would recommend that we do it once in one location and setup a new database for network data. The same grafana frontend could be used to visualize both db data and network metrics (and maybe even correlate the two?).
for our use case and size, yes… btw, sizing guidelines are here. We’re going to only see a handful of writes per minute on average… queries per second should be low at first too.
this is one area I think we should discuss. One model (my preference) is that the decoders run on the db machine itself and becomes a part of the db software, agnostic of the data warehouse. If we go with my proposal, there’s a field for “decoded” and so the task/script is just selecting all where “decoded” = 0, and iterates on the results - sending them to the data warehouse and marking them as “decoded” = 1.
So then the question is what does this task look like? Is it going to look for satellites we have decoder functions for and iterate through them? Or do we do this externally and have a script for each such satellite (yuck?)?
((and I’m not 100% comfortable with storing those decode functions in the db and just arbitrarily running them either - could introduce quite a security hole))
Agreed this is the way I envisioned it too.[quote=“cshields, post:7, topic:2359”]
If we go with my proposal, there’s a field for “decoded” and so the task/script is just selecting all where “decoded” = 0, and iterates on the results - sending them to the data warehouse and marking them as “decoded” = 1.
[/quote]
No need for that field as we already have the decoded field in the DemodData model.[quote=“cshields, post:7, topic:2359”]
So then the question is what does this task look like? Is it going to look for satellites we have decoder functions for and iterate through them?
[/quote]
I say Kaitai is the solution again here. We don’t execute random people’s code. They submit the formalized description of their packets as kaitai structs and then we generate the python parsers.
Agreed on looking into kaitai - I’ll try and take a look and implement unisat-6 with it. In the meantime, I’m dumping these relevant comments from irc here before I lose them in scrollback.
(oldbug) I was just playing a bit with katai: seems it has some problems with not byte aligned values - e.g. the FOX-Sats have their ID stored in three bits, followed by resetcount (16 bits), uptime (25 bits) and the frame type (4 bits); data is stored in big endian format but “bit-fields” are always little endian in kaitai… searching for another approach and have to read a lot of docs if there is a way around…
(oldbug) now that is really challenging: only looking at the header of such a FOX-frame, the docs say: 3 bits ID, 16 bits reset count, 25 bits uptime, 4 bits frame type which sums up to 48 bits of header, divided by 8 results in 6 bytes. docs also say: Bits shall be transmitted MSB first, bytes shall be transmitted little endian
(oldbug) what currently get in a frame (in hexadecimal presentation), for the header looks like:
(oldbug) 51 18 40 1C 17 40
(oldbug) flipping endianess for the first byte gives the ID for FOX-1A (which is correct because the frame is downloaded from a FOX-1A obs)
(oldbug) now the rest of that byte belongs to reset count
(oldbug) as reset count is stored from bit #4 up to bit #19 this is not byte-aligned and any conversion in LE or BE fails
(oldbug) but adding padding-bits is not easy and I think not effective at all
(oldbug) just a few glimps for you interested… if there are any ideas: pse ping me
(oldbug)
(oldbug) ah forgot sth: changing the endianess of the frame-bytes for the whole frame doesn’t work, because values are stored off bytealignment, as I described
I can’t figure out the ax.25 header format that would match here (aside from the protocol id of F0) so I just ignore the header and accept it as a block of data. Their beacon struct starts at the US6 sync frame. Here is what kaitai looks like decoding a frame:
Here’s the catch: our frame data in db is (all?) hexadecimal. Kaitai is going to expect binary, so there will be a conversion step in there if we automate this.
So then the question becomes: how do we handle satellites like FOX? would they even be considered in scope at this point?
One other thing to consider here: a satellite may have different frames to send. Would we allow for multiple structs to be saved for a satellite, and just try each one against each frame that came in?
So are you suggesting that the decoded data also go back to db when it goes to the data warehouse? (I’m not arguing this, just clarifying)
If so - that would allow us to easily select entries where DemodData = null, but we still need some kind of circuit breaker to prevent our task from retrying a corrupt frame over, and over, and over…
Maybe the flow goes like this (psuedocode):
task()
select * where noradid=40012 and demoddata=null
for each: run decoder
if successful: send to datawarehouse and to DemodData
else: send "failed" to DemodData
I’m trying to think of scenarios that break this model… One such case is where a satellite has multiple frame types. Let’s say we have a decoder for the typical telemetry frame, then every other frame gets flagged as “failed”. That may be okay - if we ever add support for a second frame type, we could easily go through the db and reset demoddata=null where demoddata="failed" and the other frames would be retried again.
and the more I think about this - this might be a great model. Let’s say we see some data integrity issues or improve upon the decoder model? Just reset the corresponding DemodData’s to null.
This should be done: the same frame could be fed into db from multiple observers. We would need a method to select e.g. only frames recorded by station #0815.
There has to be decided what is done in the future: simply keep the upload and conversion model or add a SiDS forwarder to, e.g., the satnogs-client? Adding a SiDS forwarder could allow to run this with multiple data-warehouses. There are some trophies to collect, IIRC.
I defined CAS-4A/CAS-4B in kaitai, see attached: cas4.ksy.txt (1.5 KB)
This one is more difficult in that it spreads the telemetry into the same bits of the same frame type, but spread across 4 consecutive frames. Still feasible in kaitai.
@DL4PD we chatted on irc about doing the math within the kaitai framework, I don’t think that will work out in a scenario like CAS-4 where value instances may get called on data types that may not exist. The more I poked at that, the more I felt we would be better off decoding the data “raw” as it were into the warehouse, and then do the calculations from there (which grafana can do).
I also spent some time this weekend working on a possible implementation in db… The kaitai python library exists solely to support the python classes that are created by the kaitai compiler. This means we will still need to compile and manage class files out of our struct definitions. Python’s Construct, on the other hand, can do the parsing in place, however they have admitted to kaitai being much better at performance (which may be critical to us in terms of the initial run of possibly millions of frames).
So… Construct would be cleaner, we could store the struct in the db entry and do the parsing in place from that struct. However, I think there may be benefits to going forward with kaitai and compiled python class files:
Encouraging the smallsat community to adopt and generate kaitai structs means that others could download the struct file from db and easily compile it into a dozen different languages.
With the kaitai graphviz output we could easily add a visual representation of the structs to db
This method allows for edge cases where kaitai-sourced decoders just won’t work and we’ll need python class decoder files anyway
My implementation proposal:
Fix the Telemetry model (if necessary) to support the assumption that “schema” will be kaitai structs
Fix the admin task that attempts a full decode for a satellite (decode_data), instead spawning a celery task. This is going to be resource intensive for the initial run, hence it is by admin command only. The decoder will pull all demoddata for the sat, iterate over each using the decoder from Telemetry, if it was successful the results go in to payload_decoded as well as into the data warehouse (payload_decoded in db may be unnecessary at this point, but I’m sure someone may have a use for it in the future so it won’t hurt)
Create a scheduled task that picks through telemetry we have a decoder for, queries for the past day/week(?) of data, and iterates over it (where payload_decoded=false). anything that can’t be decoded at this time will remain payload_decoded=false either due to corrupt data or we don’t have the decoding capabilities yet. We will want this task to run frequently, let’s say */15… This will give us near-real-time data into the warehouse.
create an admin function that allows for the “resetting” of all demodulated data for a single sat - lest a decoder have an error in it and we need to do it over (or, say, the decoder improves over time).
Proposed processes:
For the initial implementation, Telemetry entries can be managed by admins in the admin console. We can write docs on how to use kaitai’s web ide to work on a struct and suggest that the community submit their structs through community.libre.space where admins can pull from.
When a new satellite is added, someone in the dev team will need to generate the .py class file from the .ksy and commit to /db/base/decoders. Once deployed, the command can be triggered to retroactively decode all data for that satellite.
Future roadmap:
Visibility of the struct/decoder in use
multiple decoder support
“Suggest a struct” like we have suggest a transmitter
Auto generation of python modules from ksy entries?
I started implementing this tonight in db… couple of points to note:
doing this with kaitai decoders is not the prettiest. There is a bit of an assumption that you know what the object looks like when dealing with a kaitai decoder - and we are going to have a directory full of unique decoders. However, we can iterate through this, discard the things we know we don’t want (classes, other objects) and assume that the rest is valuable data.
we’ll have a USE_INFLUX setting flag. If that is set the decoded data goes to influx, otherwise it goes back to db into payload_decoded in a heavily stripped down json format (no binary, etc… not that we will be storing any binary into influx either so I guess that is a moot point).
there will be a “reset demod data” command available in admin console (mostly for testing), and a “decode all data” command in the per-satellite view. The scheduled workers will only iterate through the latest data, so these commands will be used to catch us up on old data as we add decoders.
I’ve committed this pipeline to db-dev for testing over the weekend. I’ve made an assumption in my hacky way of abstracting data from the kaitai objects that they will be flat in nature, and that won’t always be the case (as I quickly ran into with CAS-4 decoders).
As much as I would love the plug-and-play nature of an unmodified kaitai decoder working in our pipeline, its going to be too ugly to make it work. I plan to modify the pipeline to expect that the kaitai decoder scripts will all have a function added to them (get_data()?) that will return a dictionary of the telemetry fields and their values. This way the db code knows what to expect from every script and how to handle it, and the backend work that is specific to each satellite can be handled in the decoder script.
I’ll probably whip these changes up and have them in testing on db-dev next weekend.
Hey, can you expand a bit on this? We will not be storing only a kaitai struct per transmitter anymore? I would love us to find the most abstract way to do that for optimizing the crowdsourcing nature of this.