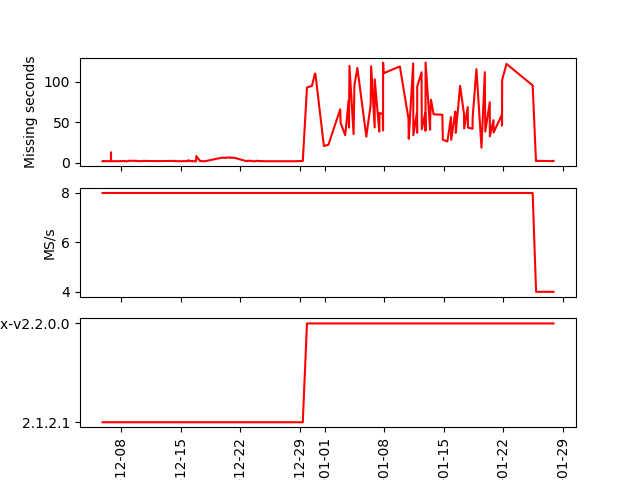
In case someone is interested in doing some similar analysis, i post the little python script used to generate the above graph:
Glouton has been called with following arguments (use start/stopdate, sat id and groundstation id as you which):
glouton -s 2021-01-20T00:00:00 -e 2021-02-10T00:00:00 -n 38771 --gsid 1868 --archive-module ObsMetadataToJsonFile
(When calling it on a too big time interval, i got http errors, probably doing too much requests in parallel, so i split them into smaller chunks (14 days).
Then i called the python script below as:
./analyzer.py archive__01-20-2021T00-00-00__02-10-2021T00-00-00/satnogs_35* .json
of course your exact path will vary. Important is to use *.json at the end to only give the json and not the audio files as argument.
Finally my anayzer.py script:
#!/usr/bin/env python3
import csv
import dateutil.parser
import json
import numpy as np
import pylab as plt
import pyogg
import sys
observations = []
# Read all observation into array
for json_filename in sys.argv[1:]:
print("Processing " + json_filename)
with open(json_filename) as json_file:
data = json.load(json_file)
start_time = dateutil.parser.parse(data['start'])
end_time = dateutil.parser.parse(data['end'])
obs_duration = (end_time - start_time).seconds
client_version = data['client_version']
client_metadata = json.loads(data['client_metadata'])
radio_version = client_metadata['radio']['version']
samplerate = float(client_metadata['radio']['parameters']['samp-rate-rx'])
# Read corresponding audio file to get recorded duration
ogg = pyogg.VorbisFile(json_filename[:-5])
# / 2. as 16 bit ?
ogg_duration = ogg.buffer_length / ogg.channels / ogg.frequency / 2.
observations.append({'start_time': start_time, 'end_time': end_time, 'obs_duration': obs_duration, 'ogg_duration': ogg_duration, 'duration_delta_in_seconds': (obs_duration - ogg_duration), 'duration_delta_in_percent': (obs_duration - ogg_duration) / obs_duration, 'client_version': client_version, 'radio_version': radio_version, 'samplerate': samplerate})
observations.sort(key=lambda obs: obs['start_time'])
# Generate output .csv and graph
g_T = []
g_Secs = []
g_Samplerate = []
g_Version = []
with open('out.csv', 'w', newline='') as csvfile:
fieldnames = ['start_time', 'end_time', 'obs_duration', 'ogg_duration', 'duration_delta_in_seconds', 'duration_delta_in_percent', 'client_version', 'radio_version', 'samplerate']
csv_writer = csv.DictWriter(csvfile, fieldnames=fieldnames, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writeheader()
for observation in observations:
csv_writer.writerow(observation)
g_T.append(observation['start_time'])
g_Secs.append(observation['duration_delta_in_seconds'])
g_Samplerate.append(observation['samplerate'] / 1000000)
g_Version.append(observation['radio_version'])
ax1 = plt.subplot(311)
plt.plot(g_T, g_Secs, 'r')
plt.setp(ax1.get_xticklabels(), visible=False)
plt.ylabel("Missing seconds")
ax2 = plt.subplot(312, sharex=ax1)
plt.plot(g_T, g_Samplerate, 'r')
plt.setp(ax2.get_xticklabels(), visible=False)
plt.ylabel("MS/s")
ax3 = plt.subplot(313, sharex=ax1)
plt.plot(g_T, g_Version, 'r')
plt.ylabel("Version")
plt.xticks(rotation='vertical')
plt.xlabel("time")
plt.savefig("out.png")