I’m happy with releasing this as a first version, it will probably need some adjustments as we discover more about this format.
4 Likes

Last pass. Decoded with a decoder from Egor UB1QBJ. Unfortunately sarajahsat_simple.py did not decode anything.

If you can share the data I can perhaps take a look at why my parser does not catch it.
The satellite, from my vantage point, was already low near the horizon when it started transmitting images. So it is certainly incomplete.
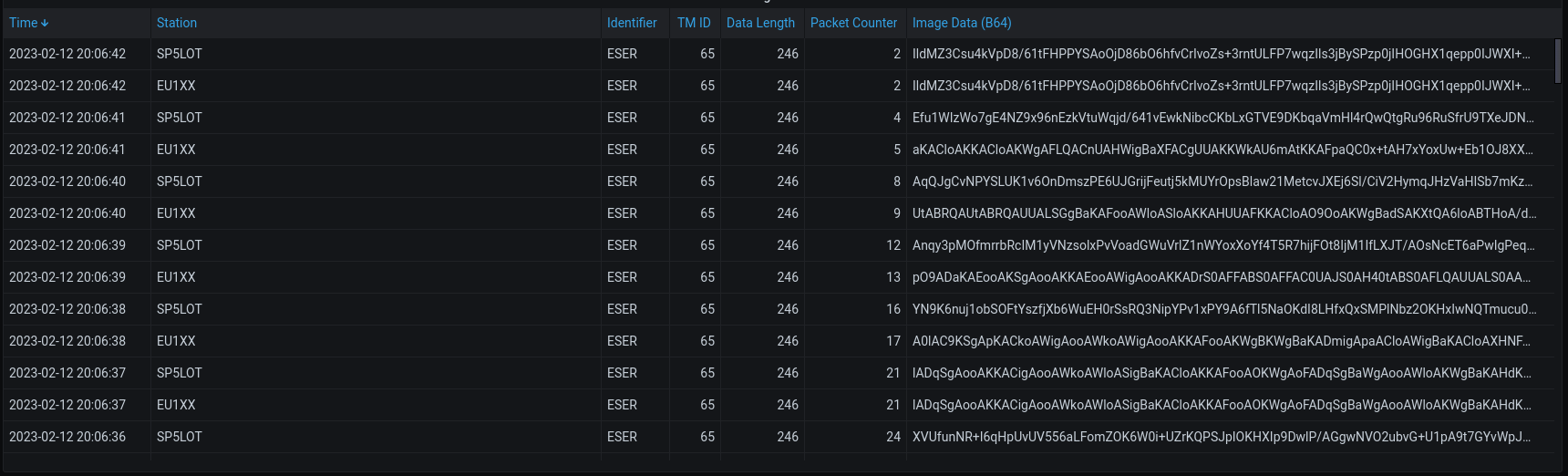
It’s too bad that each package is not numbered like ssdv. Then we would just have a hole in the image, but without the distortion.
I decoded using hs_soundmodem, then direwolf set to 9600.Direwolf decoded far fewer packets than soundmodem. Maybe some special settings are needed in direwolf ?
Can you please share a link for the decoder?
Thanks!
It is numbered!
That’s what I was talking about earlier when bringing up the header…
Unfortunately, I am not a programmer. It just seemed to me that knowing the packet number in the image transmission, we could extract the holes between the missing data and replace them with, for example, black in the image. But it is certainly not that simple. However, I have seen this effect with ssdv transmissions.
The decoder works online (windows). The command syntax is:
TCP-SharjahSat1_Images_Decoder.exe -ip 127.0.0.1 -p 8100
-p - kiss port hs_soundmodem
IQ file.
As the data packet counter shows pictures - it is very difficult to receive all the packets. There are always some missing
Reading this thread… yet another example where what is essentially a solved problem (image recovery with missing packets) is still… a problem.
The SSDV framing had this issue solved back in 2009. It doesn’t add much overhead, and can be implemented on a simple microcontroller (it was first implemented on a ATMega328!).
3 Likes
Agreed. Works well but requires large-ish frames and for it to be effective also needs to be sent in one frame, not possible on all platforms. 256B frames as default looks ok, 128B not so much, 64B as in geoscan it will just look terrible.
For this sat it should work just fine, so if possible could be tried out.
On the other hand, I kind of like the distributed recovery from many stations, it takes a bit of effort but using DB it can be done. With some effort probably can be done in the grafana dashboard.
2 Likes
Oh yes, the distributed receiver side of it is absolutely excellent for our high-altitude balloon launches. With a few stations we get almost 100% image reception during our flights.
2 Likes
Is it possible to get a .zip version please? And the python source?
I don’t have another version. I have this version from https://twitter.com/HRPTEgor Please write to him.
SHARJAHSAT-1 Image
2023-10-24
08:37:36, 08:38:35, 08:40:33, 08:41:31 UTC

6 Likes
Tried working on a decoder, it recognizes the JPEG imagery headers, however, the output JPEG image is not valid.
Can anyone please help debug?
import socket
import binascii
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except socket.error:
print('Failed to create socket')
exit()
host = "localhost"
port = 8200
s.connect((host,port))
print('Connected to ' + str(host) + ":" + str(port))
print("")
f = open("output_jpeg.txt",'w')
f_raw = open("output_raw.txt",'w')
write_JPEG = False
image_num = 0
jpeg_array = bytearray()
f_jpeg = 0
def parse_frame(frame):
global jpeg_array
global f_jpeg
global write_JPEG
global image_num
frame_imagery = frame[56:]
if "ffd9" in frame_imagery:
loc = frame_imagery.find("ffd9")
frame_imagery = frame_imagery[:loc+4]
#frame_imagery = frame
#frame_imagery_str = str(binascii.hexlify(frame_imagery)).replace("b","").replace("'","")
#print(frame_imagery)
#f.write(frame_imagery)
if "ffd8" in frame_imagery:
print("\n")
print("JPEG start header found")
write_JPEG = True
f_jpeg = open("image_"+str(image_num)+".jpg",'wb')
if write_JPEG:
#jpeg_array = jpeg_array + binascii.unhexlify(frame_imagery)
f_jpeg.write(binascii.unhexlify(frame_imagery))
f.write(frame_imagery+"\n")
f_raw.write(frame+"\n")
if "ffd9" in frame_imagery:
print("\n")
print("JPEG end header found")
write_JPEG = False
f_jpeg.close()
f_jpeg = 0
f.close()
image_num = image_num+1
while True:
frame = s.recv(16384).hex()
frame = frame[:len(frame)-2]
#frame = binascii.unhexlify(frame)
parse_frame(frame)
print("FRAME LENGTH (BITS):"+str(len(binascii.unhexlify(frame))*8))
Maybe @SA2KNG?
Hi,
I did look at the new frames and my old code again, it doesn’t handle several different images so the input file need to be filtered accordingly. I did manage to get almost the full image as seen above.
However, I think the image transmission format is a bit hard to implement, especially from DB. First off, the counter goes down so addressing with this becomes inverted. Second, even if most frames are 246B long, the last two frames (0 and 1) are not full length, which means you cannot use the counter as file position in the inverted counter*length format. You need to put the highest frame at position zero.
I need to rethink it, for now I think this could work:
- detect FFD8FF and get the highest frame count from that frame
- extract frames to list with counter as index
- yield/return array when encountering FFD8FF and a different highest frame count, indicating a new image.
The image processing then needs to loop through the list(s) and assume length 246 and use the length field when available, this to avoid zero padding.